Simple Analysis Of A CVE-2021-40444 .docx Document
Analyzing a malicious Word document like prod.docx that exploits CVE-2021-40444 is not difficult.
We need to find the malicious URL in this document. As I've shown before, this is quite simple: extract all XML files from the ZIP container (.docx files are OOXML files, that's a ZIP container with (mostly) XML files) and use a regular expression to search for URLs.
This can be done with my tools zipdump.py and re-search.py:
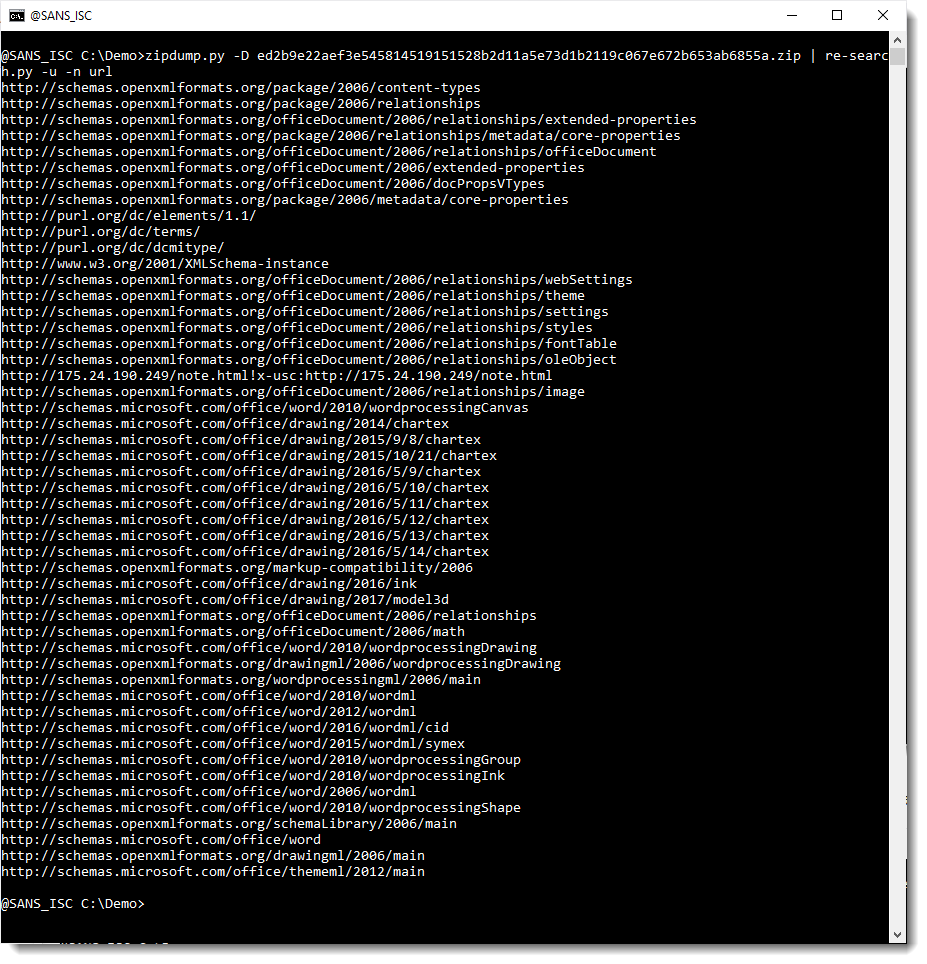
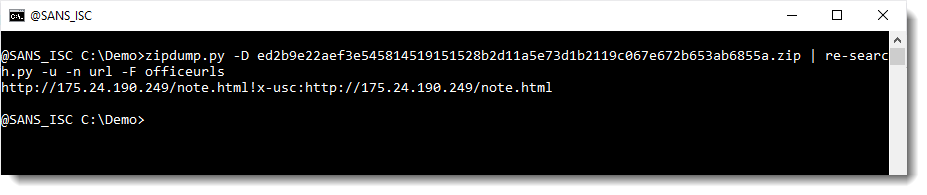
OOXML files contain a lot of legitimate URLs. Like schemas.microsoft.com. These can be filtered out with my tool re-search.py:
Didier Stevens
Senior handler
Microsoft MVP
blog.DidierStevens.com
Keywords: maldoc
0 comment(s)
Click HERE to learn more about classes Didier is teaching for SANS
×
![modal content]()
Diary Archives


Comments