Data Classification For the Masses
Data classification isn’t a brand new topic. For a long time, international organizations or military are doing "data classification”. It can be defined as:
“A set of processes and tools to help the organization to know what data are used, how they are protected and what access levels are implemented”
Military’s levels are well known: Top Secret, Secret, Confidential, Restricted, Unclassified.
But organizations are free to implement their own scheme and they are deviations. NATO is using: Cosmic Top Secret (CTS), NATO Secret (NS), NATO Confidential (NC) and NATO Restricted (NR). EU institutions are using: EU Top Secret, EU Secret, EU Confidential, EU Restricted. The most important is to have the right classification depending on your business!
Data classification is not only used by IT teams but also by all data, applications or process owners in the organization. The implementation of data classification is definitively not an easy process but will more and more become mandatory, especially in Europe. EU adopted a new regulation called “General Data Protection Regulation” (GDPR) [1] that will be effective by May 2018. Its goal is to protect users data. To resume the new rules regarding data:
- Organizations will need the user’s consent before collection PI (“Personal Information”).
- Data must be wiped after a predetermined period
- In case of a data breach, users and authorities must be notified within 72 hours.
The last point is critical because according to a study [2], most companies take over six months to detect data breaches! And data classification help you to better protect your data. The process is based on the following steps:
- Identify (assets, data)
- Create your protection profiles
- Deploy the protection profiles and enforce them
- Review
- Reclassify data & improve
Don't be fooled, this is a very complex process. Even the first step can be very difficult for many organizations but, once it's done, it's easy to label any new type of data. We see that more and more products and tools started to take care of privacy and data classification. Two examples: Microsoft launched the “Windows Information Protection”[3] (for Windows 10 Anniversary Update & Office 365 Pro) which includes features to identify different types of information, determine which apps have access to it, and provide the basic controls (example: Copy and Paste restrictions). The open source world also embraces data classification. The latest LibreOffice release provides document classification according to the TSCP standard[5].
You can also implement a basic data classification at the operating systems level. Modern OS can apply “tags” on files and directories. On my Macbook, I defined the TLP standards and apply them to some of my files:
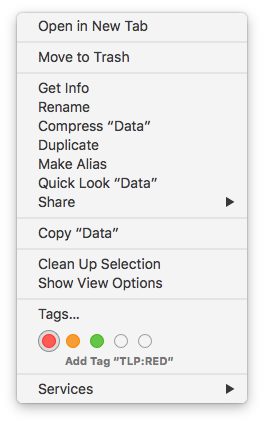
Some Linux distributions implement also a system to tag files. Via the GUI (here Nautilus):
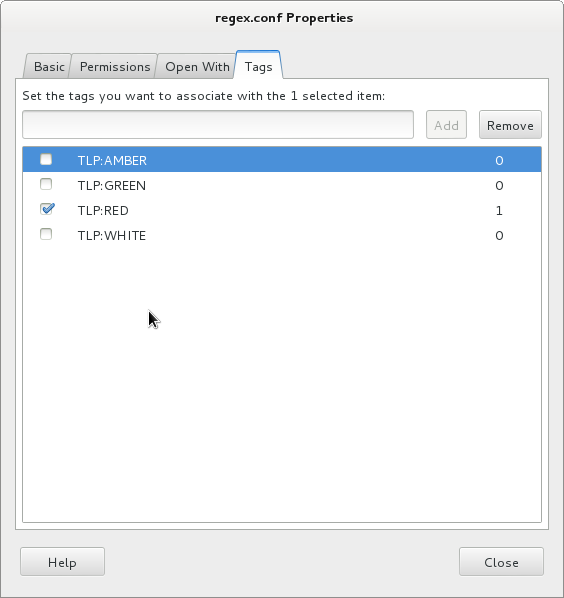
But you can perform the same from the command line (read: on servers too). Here is an example based on Debian. If not available by default, install the required tools[6]:
# apt-get install tracker-utils
Then, enable the indexing services:
# tracker-control -s
You can now add tags to files:
# touch super-secret.txt # tracker-add -a TLP:RED super-secret.txt Tag was added successfully Tagged: file:///root/super-secret.txt
Now you can search for tagged files:
# tracker-tag -t -s TLP:RED
Tags (shown by name):
TLP:RED
file:///root/super-secret.txt
To conclude this diary, my advice is to keep in mind that data classification will get more and more focus in the near future. Be ready to kick off such project inside your organization. And you? Did you already implement data classification? Do you have plans? Please share your tips.
[1] https://en.wikipedia.org/wiki/General_Data_Protection_Regulation
[2] http://www.zdnet.com/article/businesses-take-over-six-months-to-detect-data-breaches/
[3] https://blogs.technet.microsoft.com/windowsitpro/2016/06/29/introducing-windows-information-protection/
[4] https://blog.documentfoundation.org/blog/2016/08/03/libreoffice-5-2-fresh-released-for-windows-mac-os-and-gnulinux/
[5] https://www.tscp.org/
[6] https://packages.debian.org/sid/tracker
Xavier Mertens (@xme)
ISC Handler - Freelance Security Consultant
PGP Key


Comments
Thank you for this very interesting article.
You mentioned a rule from the data protection regulation: "In case of a data breach, users and authorities must be notified within 72 hours."
What would "data breach" mean? I contacted the ICO directly to get an answer to the definition and she/he simply sent me a link to the glossary[1], which you may guess, does not explain what a breach is according to the GDPR.
I looked into several English dictionaries (Oxford, Cambridge, Larousse, Reverso, etc.). They give two definitions to the word 'breach':
1) the consequence of exploitation of a vulnerability,
2) the discovery of a vulnerability.
Now, let's consider the situation in which a critical security vulnerability is suddenly discovered in a major e-commerce or bank website and reported publicly. The company doesn't have the capability to ascertain whether the vulnerability was or was not exploited (due to missing or insufficient logging, typically). That would constitute a breach, according to dictionaries but I am not sure it would according to the GDPR.
I also asked this same question to several of my colleagues, they all have a different answer. What is your position on this?
kind regards,
a.f.
1: https://ico.org.uk/for-organisations/guide-to-data-protection/key-definitions/
Anonymous
Aug 19th 2016
9 years ago
"A breach should be considered as adversely affecting the personal data or privacy of a data subject where it could result in, for example, identity theft or fraud, physical harm, significant humiliation or damage to reputation."
This is the result of the data breach.
Causes can be multiple:
- New vulnerability on a piece of software
- Bad (or default configuration) in a software or hardware
- Malicious insider
- Theft (remote backup material stolen at a contractor's premises)
- ...
From the same document, this paragraph is also interesting:
"In order to determine whether a personal data breach is notified to the supervisory authority and to the data subject without undue delay, it should be ascertained whether the controller has implemented and applied appropriate technological protection and organisational measures to establish immediately whether a personal data breach has taken place and to inform promptly the supervisory authority and the data subject, before a damage to personal and economic interests occurs, taking into account in particular the nature and gravity of the personal data breach and its consequences and adverse effects for the data subject."
To resume: tools & procedures must be implemented to detect "ASAP" a data breach.
[1] http://ec.europa.eu/justice/data-protection/document/review2012/com_2012_11_en.pdf
Anonymous
Aug 19th 2016
9 years ago
Thanks for your article on this very interesting and important subject
I'm sorry but could you give me a direct link to the TSCP standard you talk about ; second and certainly dumb question, but I don't know the meaning of the TLP acronym ?
Thanks in advance,
Anonymous
Aug 19th 2016
9 years ago
http://datatags.org/
Anonymous
Aug 19th 2016
9 years ago
The keyword/category functionality as shown, is also pervasive in Windows also. Most applications and file types support this, usually under properties. Sort by Tag is much better functionality than sorting by the standard properties like date modified or file type. These are attributes separate from typical classifications. If your only tags/keywords are "public", "privacy", "sensitive" and "confidential" (or red-amber-green-white), then you can use this function to classify. I suspect, however, that this would be a misuse of the keyword/tag function. Most uses will implement tags/keywords quite widely - I use 10-20 depending on project. For large scale categorization, one can use SP 800-60 which takes a functional approach for guidance (it is huge and a lengthy list-pick only the ones you need to slim it down). Again, this is categorization, not classification.
Classification is on the other hand probably more brittle. Your military example is adequately descriptive. However, there are actually more add-ons available for distribution qualifiers (supplement FOUO-Secret-Top Secret classification). The Traffic Light Protocol (TLP) is another-Red-Amber-Green-White. In practice, TLP is used for describing distribution, so that technically can be considered a subset of classification (as I noted regarding military classification and distribution). Another approach I mentioned above - public-privacy-sensitive-confidential, probably works for most (unless you have trade secrets or intellectual property, for example, which should get other classifications).
Best Practice should include the implementation and usage of both Classification and Categorization.
Anonymous
Aug 19th 2016
9 years ago
Thanks for your article on this very interesting and important subject
I'm sorry but could you give me a direct link to the TSCP standard you talk about ; second and certainly dumb question, but I don't know the meaning of the TLP acronym ?
Thanks in advance,[/quote]
TLP == Traffic Light Protocol (https://www.us-cert.gov/tlp)
Anonymous
Aug 19th 2016
9 years ago
http://datatags.org/[/quote]
Thank you for sharing this useful resource!
Anonymous
Aug 19th 2016
9 years ago
Useful piece of information!
Anonymous
Aug 19th 2016
9 years ago
There are two volumes to the 800-60. Volume I is where the meat and potatoes guidance for data categorization.
http://nvlpubs.nist.gov/nistpubs/Legacy/SP/nistspecialpublication800-60v1r1.pdf
Obviously, much of what is in the publication is geared toward US Federal agencies and systems, but the guidance can be easily applied to any data environment.
In my efforts to find examples of data categorization/classification, I found these 2 online representations:
https://security.uic.edu/data-classifications/
http://www.cmu.edu/iso/governance/guidelines/data-classification.html
(The CMU example is excellent IMHO).
Just sharing what I have learned.
:-)
Anonymous
Aug 19th 2016
9 years ago
Anonymous
Aug 20th 2016
9 years ago