Ransomware & Entropy
Last time I helped out someone with ransomware over at the Bleeping Computer forums, I was able to recover the ransomed JPEG files.
A first look at the file with the file command did not help me:
file image.jpg.xxx\@yyy.zz
image.jpg.xxx@yyy.zz: data
Neither did a look at the header with a hex editor tell me much more.
But when I analyzed the file with one of my tools to calculate byte statistics (byte-stats.py), I noticed something:
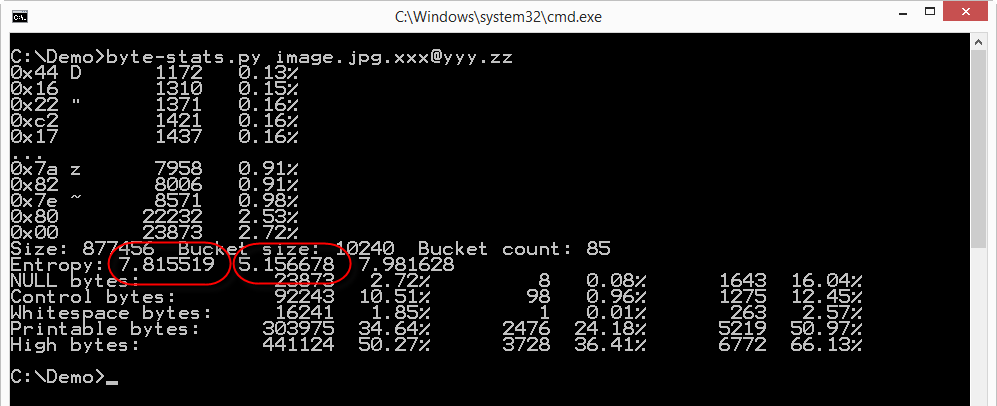
The file has a high byte entropy: 7.815519, that's almost the maximum (8.0). So the file appears to be a set of random bytes, e.g. an encrypted file.
But my program not only calculates the entropy for the whole file (along with other properties), but it also splits the file in buckets (10KB size by default) and calculates the entropy (and other properties) for each bucket. The second entropy value produced by the analysis (5.156678) is the lowest entropy calculated for the buckets (85 in total for this file). And an entropy of 5 is much lower than the entropy of encrypted or compressed data. So somewhere in this file there is data that doesn't look very random.
A picture is worth a thousand words is the saying. bytes-stats.py can also output the entropy for each bucket (option -l), which enabled me to produce this graph:
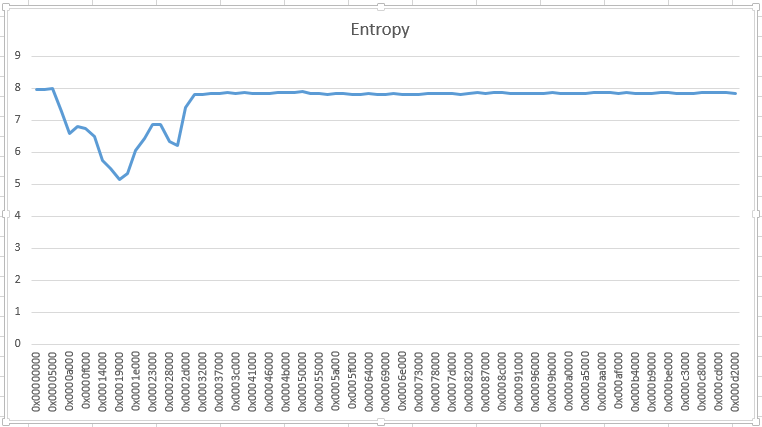
Somewhere around position 0x5000, data doesn't look random. I took a look with my hex editor, and quickly recognized JPEG structures. What was missing were the first headers of a JPEG file. So I patched a file together with the header of a JPEG file followed by the data recovered from the ransomed file. And to my surprise, I had recovered the image.
I had no luck when I analyzed a ransomed .doc file from the same victim:
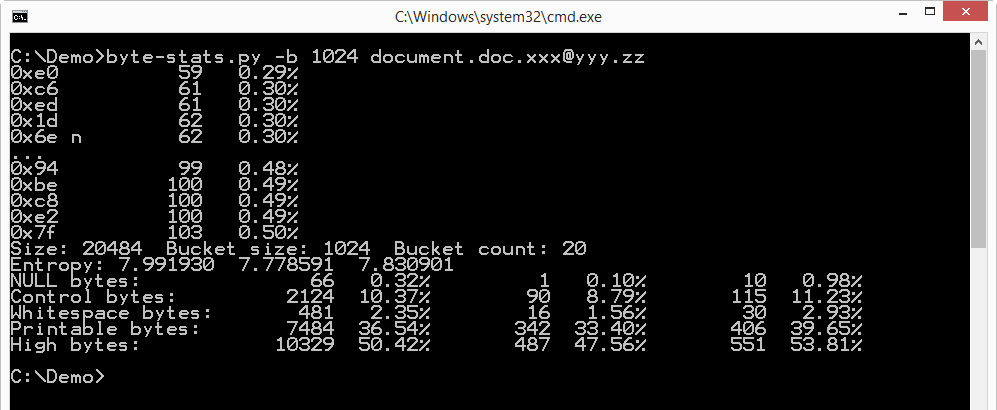
The entropy of this file looks uniformly high.
I often look at the entropy when I analyze files. Many of my analysis tools include entropy calculations. For example, pecheck.py provides the entropy of each section of a PE file, allowing me to quickly identify packed sections.
Didier Stevens
Microsoft MVP Consumer Security
IT Security consultant at Contraste Europe.
blog.DidierStevens.com DidierStevensLabs.com


Comments
Really nice article. Just had one query. How did you patch the different buckets having similar entropy value and JPEG header? And is is possible to do this for other types of files as well?
Anonymous
Oct 19th 2015
1 decade ago
So I just created a file: \xFF\xD8\xFF\xE0\x00\x10\x4A\x46\x49\x46\x00\x01\x01\x01\x00\x48\x00\x48\x00\x00 + JPEG data from the "encrypted" file. And this was a valid picture.
You can find more details (along with a Python program I wrote) in the BC forums post: http://www.bleepingcomputer.com/forums/t/590988/brainless-rookie-ransomware-what-ransomware/page-3
It did only work for JPEG files, I did not recognize any structure in the ransomed .doc file.
Anonymous
Oct 19th 2015
1 decade ago
One question though. In your recovery program, you look for hex string FF DB 00 C5 (content.find('\xFF\xDB\x00\xC5')). Why C5? Every jpg of mine I looked at, that string didn't appear. FF DB 00 43 did though.
Anonymous
Oct 19th 2015
1 decade ago
A quantization table is 0x40 bytes + 1. So that's a length of 00 43 (0x41 + 2).
You have one quantization table in your pictures.
The victim had 3 quantization tables in his pictures (3 * (0x40 + 1) + 2 = C5).
When I used just the marker FF DB to search the ransomed files, I had false positives.
So I decided to search for FF DB 00 C5, but the down side is that the program only works for the victim's pictures.
Anonymous
Oct 21st 2015
1 decade ago
Anonymous
Oct 21st 2015
1 decade ago
So it means that compressed image data [after SOS marker 0xFFDA] were untouched by ransomware?
Or despite encryption of compressed image data, the jpeg image (after header reconstruction) was visually the same image?
Anonymous
Oct 30th 2015
1 decade ago
What was lost was the EXIF data.
Anonymous
Oct 31st 2015
1 decade ago