Bridging Datacenters for Disaster Recovery - Virtually
It's been a while since we talked about Disaster Recovery issues - the last diary I posted on this was on using L2TPv3 to bridge your Datacenter / Server VLAN to the "same" VLAN at a DR site, over an arbitrary Layer 3 network (https://isc.sans.edu/diary/8704)
Since then, things have changed. There's a real push to move DR sites from a rack in a remote office location to recognized IaaS cloud locations. With that change comes new issues. If you are using your own servers in a colocation facility, or using IaaS VM instances, rack space for a physical router may either come with a price tag, or if it's all virtual, there might be no rack space at all.
In my situation, I had two clients in this position. The first customer simply wanted to move their DR site from a branch office to a colocation facility. The second customer is a Backup-as-a-Service Cloud Service Provider, who is creating a "DR as a service" product. In the first situation, there was no rack space to be had. In the second situation, the last thing a CSP wants is to have to give up physical rack space for every customer, and then deploy CSP owned hardware to the client site - that simply does not scale. In both cases, a VM running a router instance was clearly the preferred (or only) choice.
Virtual routers with enterprise features have been around for a while - back in the day we might have looked at quagga or zebra, but those have been folded into more mature products these days. In our case, we were looking at Vyatta (now owned by Brocade), or the open-source (free as in beer) fork of Vyatta - Vyos (vyos.net). Cisco is also in the game, their 1000V product supports IOS XE - their "bridge L2 over L3" approach uses OTV rather than L2TPv3 or GRE. You'll find that most router vendors now have a virtual product.
Anyway, Working with Vyatta/Vyos configs isn't like Cisco at all - their configs look a whole lot more like you might see in JunOS. While Vyos supports the L2TPv3 protocol we know and love, it's a brand new feature, and it comes with a note from the developer "if you find any bugs, send me an email" (confidence inspiring, that). Vyatta doesn't yet have that feature implemented. So I decided to use GRE tunnels, and bridge them to an ethernet interface. Since this tunnel was going to run over the public internet, I encrypted/encapsulated the whole thing using a standard site-to-site IPSEC tunnel. The final solution looks like this:
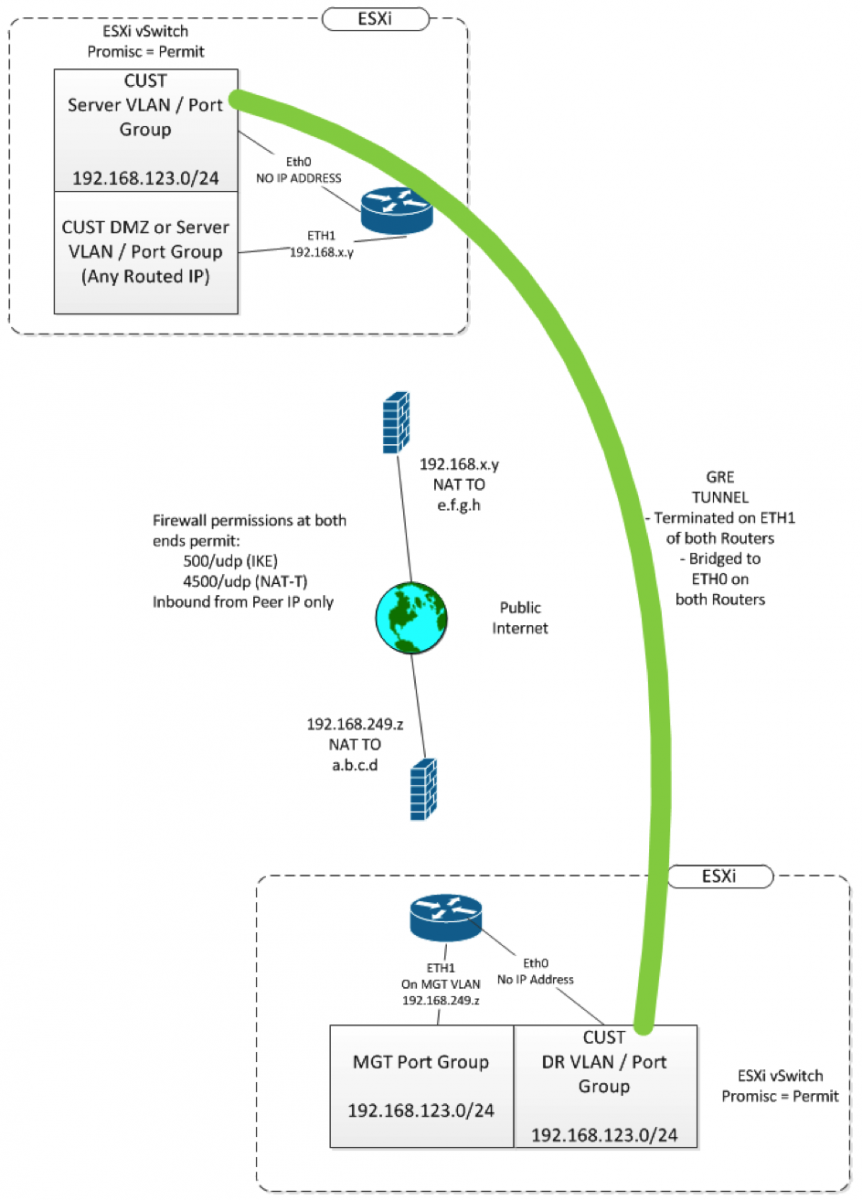
The relevant configs look like the one below (just one end is shown) Note that this is not the entire config, and all IP's have been elided.
Please - use our comment form and let us know if you've used a different method of bridging Layer 2 over Layer 3, and what pitfalls you might have had to overcome along the way!
|
interfaces { bridge br0 { aging 300 hello-time 2 max-age 20 priority 0 stp false } |
First, define the bridge interface. Not that STP (Spanning Tree Protocol) is disabled. You likely want this disabled unless you’ve got a parallel second bridged link (maybe a dark fiber or something similar) |
|
ethernet eth0 { bridge-group { bridge br0 } description BRIDGE duplex auto hw-id 00:50:56:b1:3e:4f mtu 1390 smp_affinity auto speed auto } |
The ETH0 interface is on the server VLAN (or port group if you are using standard ESXi vSwitches) – this is the VLAN that you are bridging to the DR site. It is added to the bridge, and has no IP address. |
|
ethernet eth1 { address 192.168.123.21/24 duplex auto hw-id 00:50:56:b1:1d:a8 smp_affinity auto speed auto } |
ETH1 is the management IP of this router, and is also the terminator for the GRE tunnel and the IPSEC VPN. You can split this up, many might prefer to terminate the tunnels to a loopback for instance, or add another Ethernet if you prefer. |
|
tunnel tun0 { description BRIDGED encapsulation gre-bridge local-ip 192.168.123.21 multicast enable parameters { ip { bridge-group { bridge br0 } tos inherit } } remote-ip 192.168.249.251 } } |
The GRE tunnel is also bridged, and also doesn’t have an IP address. The encapsulation of GRE-bridge is the same as GRE (IP protocol 47), but the “gre-bridge” encapsulation allows you to add this interface to bridge. |
|
..... system stuff like AAA, NTP, timezone, syslog, SSH, ACLs and so on go here ...... |
This stuff is all important for your security posture, but is not relevant to the tunneling or bridging, so I’ve redacted it. |
|
vpn { ipsec { esp-group PRL-ESP { compression disable lifetime 3600 mode tunnel pfs disable proposal 1 { encryption AES256 hash sha1 } } ike-group PRL-IKE { lifetime 28800 proposal 1 { encryption AES256 hash sha1 } } ipsec-interfaces { interface eth1 } logging { log-modes all } nat-traversal enable site-to-site { peer a.b.c.d { authentication { id @CUSTOMER mode pre-shared-secret pre-shared-secret demo123 remote-id @CLOUD } connection-type initiate default-esp-group PRL-ESP ike-group PRL-IKE local-address 192.168.123.21 tunnel 0 { allow-nat-networks disable allow-public-networks disable esp-group PRL-ESP local { prefix 192.168.123.21/32 } protocol gre remote { prefix 192.168.249.251/32 } } } } } } |
The relevant portions of the VPN config are:
· We set both ends to "initiate", which enables both init and respond. This allows either end to start the tunnel |
===============
Rob VandenBrink
Metafore
What's Wrong with Bridging Datacenters together for DR?
With two stories on the topic of bridging datacenters, you'd think I was a real believer. And, yes, I guess I am, with a couple of important caveats.
The first is encapsulation overhead. As soon as you bridge using encapsulation, the maximum allowed transported packet size will shrink, then shrink again when you encrypt. If your Server OS's aren't smart about this, they'll assume that since it's all in the same broadcast domain, a full packet is of course OK (1500 bytes in most cases, or up to 9K if you have jumbo frames enabled). You'll need to test for this - both for replication and the failed-over configuration - as part of your design and test phase.
The second issue si that if you bridge datacenters to a DR or second (active) datacenter site, you are well positioned to fail over the entire server farm, as long as you can fail over your WAN connection and Internet uplink with them. If you don't, you end up with what Greg Ferro calls a "network traffic trombone". (http://etherealmind.com/vmware-vfabric-data-centre-network-design/)
If you fail one server over, or if you fail over the farm and leave the WAN links behind, you find that the data to and from the server will traverse that inter-site link multiple times for any one customer transaction.
For instance, let's say that you've moved the active instance of your mail server to the DR Site. To check an email, a packet will arrive at the primary site, traverse to the mail server at site B, then go back to site A to find the WAN link to return to the client. Similarly, inbound email will come in on the internet link, but then have to traverse that inter-site link to find the active mail server.
Multiply that by the typical email volume in a mid-sized company, and you can see why this trombone issue can add up quickly. Even with a 100mb link, folks that were used to GB performance will now see their bandwidth cut to 50mb or likely less than that, with a comensurate impact on response times. If you draw this out, you do get a nice representation of a trombone - hence the name.
What this means is that you can't design your DR site for replication and stop there. You really need to design it for use during the emergency cases you are planning for. Consider the bandwidth impacts when you fail over a small portion of your server farm, and also what happens when your main site has been taken out (short or longer term) by a fire or electrical event - will your user community be happy with the results?
Let us know in our comment section how you have designed around this "trombone" issue, or if (as I've seen at some sites), management has decided to NOT spend the money to account for this.
===============
Rob VandenBrink
Metafore


Comments